click here complete Lecture Notes: Computer Networks
Unix Socket Programming
Client Server Architecture
In the client server architecture, a machine(refered as client) makes a request to connect to another machine (called as server) for providing some service. The services running on the server run on known ports(application identifiers) and the client needs to know the address of the server machine and this port in order to connect to the server. On the other hand, the server does not need to know about the address or the port of the client at the time of connection initiation. The first packet which the client sends as a request to the server contains these informations about the client which are further used by the server to send any information. Client acts as the active device which makes the first move to establish the connection whereas the server passively waits for such requests from some client.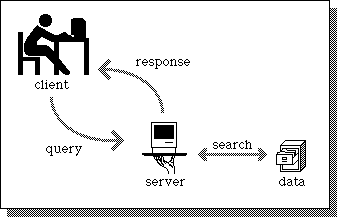
Illustration of Client Server Model
What is a Socket ?
In unix, whenever there is a need for inter process communication within the same machine, we use mechanism like signals or pipes(named or unnamed). Similarly, when we desire a communication between two applications possibly running on different machines, we need sockets. Sockets are treated as another entry in the unix open file table. So all the system calls which can be used for any IO in unix can be used on socket. The server and client applications use various system calls to conenct which use the basic construct called socket. A socket is one end of the communication channel between two applications running on different machines.Steps followed by client to establish the connection:
- Create a socket
- Connect the socket to the address of the server
- Send/Receive data
- Close the socket
- Create a socket
- Bind the socket to the port number known to all clients
- Listen for the connection request
- Accept connection request
- Send/Receive data
Basic data structures used in Socket programming
Socket Descriptor: A simple file descriptor in Unix.| int |
struct sockaddrs {
unsigned short sa_family; // address family, AF_xxx or PF_xxx
char sa_data[14]; // 14 bytes of protocol address
};
|
Name Purpose
AF_UNIX, AF_LOCAL Local communication
AF_INET IPv4 Internet protocols
AF_INET6 IPv6 Internet protocols
AF_IPX IPX - Novell protocols
AF_NETLINK Kernel user interface device
AF_X25 ITU-T X.25 / ISO-8208 protocol
AF_AX25 Amateur radio AX.25 protocol
AF_ATMPVC Access to raw ATM PVCs
AF_APPLETALK Appletalk
AF_PACKET Low level packet interface
In all the sample programs given below, we will be using AF_INET.
struct sockaddr_in: This construct holds the information about the address family, port number, Internet address,and the size of the struct sockaddr.
struct sockaddr_in {
short int sin_family; // Address family
unsigned short int sin_port; // Port number
struct in_addr sin_addr; // Internet address
unsigned char sin_zero[8]; // Same size as struct sockaddr
};
|
Some systems (like x8086) are Little Endian i-e. least signficant byte is stored in the higher address, whereas in Big endian systems most significant byte is stored in the higher address. Consider a situation where a Little Endian system wants to communicate with a Big Endian one, if there is no standard for data representation then the data sent by one machine is misinterpreted by the other. So standard has been defined for the data representation in the network (called Network Byte Order) which is the Big Endian. The system calls that help us to convert a short/long from Host Byte order to Network Byte Order and viceversa are
- htons() -- "Host to Network Short"
- htonl() -- "Host to Network Long"
- ntohs() -- "Network to Host Short"
- ntohl() -- "Network to Host Long"
IP addresses
Assuming that we are dealing with IPv4 addresses, the address is a 32bit integer. Remembering a 32 bit number is not convenient for humans. So, the address is written as a set of four integers seperated by dots, where each integer is a representation of 8 bits. The representation is like a.b.c.d, where a is the representation of the most significant byte. The system call which converts this representation into Network Byte Order is:int inet_aton(const char *cp, struct in_addr *inp); |
For example, if we want to initialize the sockaddr_in construct by the IP address and desired port number, it is done as follows:
struct sockaddr_in sockaddr;
sockaddr.sin_family = AF_INET;
sockaddr.sin_port = htons(21);
inet_aton("172.26.117.168", &(sockaddr.sin_addr));
memset(&(sockaddr.sin_zero), '\0', 8);
|
Socket System Call
A socket is created using the system call:int socket( domain , type , protocol); |
- Domain: It specifies the communication domain. It takes one of the predefined values described under the protocol family and address family above in this lecture.
- Type: It specifies the semantics of communication , or the type of service that is desired . It takes the following values:
- SOCK_STREAM : Stream Socket
- SOCK_DGRAM : Datagram Socket
- SOCK_RAW : Raw Socket
- SOCK_SEQPACKET : Sequenced Packet Socket
- SOCK_RDM : Reliably Delivered Message Packet
- Protocol: This parameter identifies the protocol the socket is supposed to use . Some values are as follows:
- IPPROTO_TCP : For TCP (SOCK_STREAM)
- IPPROTO_UDP : For UDP (SOCK_DRAM)
Bind System Call
The system call bind associates an address to a socket descriptor created by socket.int bind ( int sockfd , struct sockaddr *myaddr , int addrlen ); |
Other System Calls and their Functions
LISTEN : Annoumce willingness to accept connections ; give queue size.ACCEPT : Block the caller until a commwction attempt arrives.
CONNECT : Actively attempt to establish a connection.
SEND : Send some data over the connection.
RECIEVE : Recieve sme data from the connection.
CLOSE : Release the connection.
Client-Server Communication Overview
The analogy given below is often very useful in understanding many such networking concepts. The analogy is of a number of people in a room communicating with each other by way of talking. In a typical scenario, if A has to talk to B, then he would call out the name of B and only if B was listening would he respond. In case B responds, then one can say that a connection has been established. Henceforth until both of them desire to communicate, they can carry out their conversation. A Client-Server architecture generally employed in networks is also very similar in concept. Each machine can act as a client or a server.Server: It is normally defined which provides some sevices to the client programs. However, we will have a deeper look at the concept of a "service" in this respect later. The most important feature of a server is that it is a passive entiry, one that listens for request from the clients.
Client: It is the active entity of the architecture, one that generated this request to connect to a particular port number on a particular server
Communication takes the form of the client process sending a message over the network to the server process. The client process then waits for a reply message. When the server process gets the request, it performs the requested work and sends back a reply.The server that the client will try to connect to should be up and running before the client can be executed. In most of the cases, the servers runs continuously as a daemon.
There is a general misconception that servers necessarily provide some service and is therefore called a server. For example an e-mail client provides as much service as an mail server does. Actually the term service is not very well defined. So it would be better not to refer to the term at all. In fact servers can be programmed to do practically anything that a normal application can do. In brief, a server is just an entity that listens/waits for requests.
To send a request, the client needs to know the address of the server as well as the port number which has to be supplied to establish a connection. One option is to make the server choose a random number as a port number, which will be somehow conveyed to the client. Subsequently the client will use this port number to send requests. This method has severe limitations as such information has to be communicated offline, the network connection not yet being established. A better option would be to ensure that the server runs on the same port number always and the client already has knowledge as to which port provides which service. Such a standardization already exists. The port numbers 0-1023 are reserved for the use of the superuser only. The list of the services and the ports can be found in the file /etc/services.
Connection Oriented vs Connectionless Communication
Connection Oriented Communication
Analogous to the telephone network.The sender requests for a communication (dial the number), the receiver gets an indication (the phone ring) the receiver accepts the connection (picks up the phone) and the sender receives the acknowledgment (the ring stops). The connection is established through a dedicated link provided for the communication. This type of communication is characterized by a high level of reliability in terms of the number and the sequence of bytes.Connectionless Communication
Analogous to the postal service. Packets(letters) are sent at a time to a particular destination. For greater reliability, the receiver may send an acknowledgement (a receipt for the registered letters). Based on this two types of communication, two kinds of sockets are used:- stream sockets: used for connection-oriented communication, when reliability in connection is desired.
- datagram sockets: used for connectionless communication, when reliability is not as much as an issue compared to the cost of providing that reliability. For eg. streaming audio/video is always send over such sockets so as to diminish network traffic.
Sequence of System Calls for Connection Oriented communication
The typical set of system calls on both the machines in a connection-oriented setup is shown in Figure below.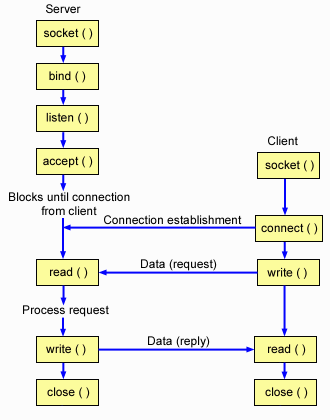
- The socket system call is used to obtain a socket descriptor on
both the client and the server. Both these calls need not be synchronous or
related in the time at which they are called.The synopsis is given below:
#include<sys/types.h> #include<sys/socket.h> int socket(int domain, int type, int protocol); - Both the client and the server 'bind' to a particular port on their
machines using the bind system call. This function has to be called
only after a socket has been created and has to be passed the socket
descriptor returned by the socket call. Again this binding on both the
machines need not be in any particular order. Moreover the binding procedure
on the client is entirely optional. The bind system call requires the
address family, the port number and the IP address. The address family is
known to be AF_INET, the IP address of the client is already known to the
operating system. All that remains is the port number. Of course the
programmer can specify which port to bind to, but this is not necessary. The
binding can be done on a random port as well and still everything would work
fine. The way to make this happen is not to call bind at all.
Alternatively bind can be called with the port number set to 0. This
tells the operating system to assign a random port number to this socket.
This way whenever the program tries to connect to a remote machine through
this socket, the operating system binds this socket to a random local port.
This procedure as mentioned above is not applicable to a server, which has to
listen at a standard predetermined port.
- The next call has to be listen to be made on the server. The
synopsis of the listen call is given below.
skfd is the socket descriptor of the socket on which the machine should start listening.#include<sys/socket.h> int listen(int skfd, int backlog);
backlog is the maximum length of the queue for accepting requests.
The connect system call signifies that the server is willing to accept connections and thereby start communicating.
Actually what happens is that in the TCP suite, there are certain messages that are sent to and fro and certain initializations have to be performed. Some finite amount of time is required to setup the resources and allocate memory for whatever data structures that will be needed. In this time if another request arrives at the same port, it has to wait in a queue. Now this queue cannot be arbitrarily large. After the queue reaches a particular size limit no more requests are accepted by the operating system. This size limit is precisely the backlog argument in the listen call and is something that the programmer can set. Today's processors are pretty speedy in their computations and memory allocations. So under normal circumstances the length of the queue never exceeds 2 or 3. Thus a backlog value of 2-3 would be fine, though the value typically used is around 5.Note that this call is different from the concept of "parallel" connections.The established connections are not counted in n. So, we may have 100 parallel connection running at a time when n=5.
- The connect function is then called on the client with three
arguments, namely the socket descriptor, the remote server address and the
length of the address data structure. The synopsis of the function is as
follows:
This function initiates a connection on a socket.#include<sys/socket.h> #include<netinet/in.h> /* only for AF_INET , or the INET Domain */ int connect(int skfd, struct sockaddr* addr, int addrlen);
skfd is the same old socket descriptor.
addr is again the same kind of structure as used in the bind system call. More often than not, we will be creating a structure of the type sockaddr_in instead of sockaddr and filling it with appropriate data. Just while sending the pointer to that structure to the connect or even the bind system call, we cast it into a pointer to a sockaddr structure. The reason for doing all this is that the sockaddr_in is more convenient to use in case of INET domain applications. addr basically contains the port number and IP address of the server which the local machine wants to connect to. This call normally blocks until either the connection is established or is rejected.
addrlen is the length of the socket address structure, the pointer to which is the second argument.
- The request generated by this connect call is processed by the
remote server and is placed in an operating system buffer, waiting to be
handed over to the application which will be calling the accept
function. The accept call is the mechanism by which the
networking program on the server receives that requests that have been
accepted by the operating system. This synopsis of the accept system
call is given below.
skfd is the socket descriptor of the socket on which the machine had performed a listen call and now desires to accept a request on that socket.#include<sys/socket.h> int accept(int skfd, struct sockaddr* addr, int addrlen);
addr is the address structure that will be filled in by the operating system by the port number and IP address of the client which has made this request. This sockaddr pointer can be type-casted to a sockaddr_in pointer for subsequent operations on it.
addrlen is again the length of the socket address structure, the pointer to which is the second argument.
This function accept extracts aconnection on the buffer of pending connections in the system, creates a new socket with the same properties as skfd, and returns a new file descriptor for the socket.
In fact, such an architecture has been criticized to the extent that the applications do not have a say on what connections the operating system should accept. The system accepts all requests irrespective of which IP, port number they are coming from and which application they are for. All such packets are processed and sent to the respective applications, and it is then that the application can decide what to do with that request.
The accept call is a blocking system call. In case there are requests present in the system buffer, they will be returned and in case there aren't any, the call simply blocks until one arrives.
This new socket is made on the same port that is listening to new connections. It might sound a bit weird, but it is perfectly valid and the new connection made is indeed a unique connection. Formally the definition of a connection is
For each connection at least one of these has to be unique. Therefore multiple connections on one port of the server, actually are different.connection: defined as a 4-tuple : (Local IP, Local port, Foreign IP, Foreign port)
- Finally when both connect and accept return the connection
has been established.
- The socket descriptors that are with the server and the client can now be
used identically as a normal I/O descriptor. Both the read and the
write calls can be performed on this socket descriptor. The close
call can be performed on this descriptor to close the connection. Man pages on
any UNIX type system will furnish further details about these generic I/O
calls.
- Variants of read and write also exist, which were
specifically designed for networking applications. These are recv and
send.
Except for the flags argument the rest is identical to the arguments of the read and write calls. Possible values for the flags are:#include<sys/socket.h> int recv(int skfd, void *buf, int buflen, int flags); int send(int skfd, void *buf, int buflen, int flags);
used formacro for the flagcommentrecvMSG_PEEKlook at the message in the buffer but do not consider it read sendMSG_DONT_ROUTEsend message only if the destination is on the same network, i.e. directly connected to the local machine. recv & sendMSG_OOBused for transferring data out of sequence, when some bytes in a stream might be more important than others. - To close a particular connection the shutdown call can also be used
to achieve greater flexibility.
skfd is the socket descriptor of the socket which needs to be closed.#include<sys/socket.h> int shutdown(int skfd, int how);
how can be one of the following:
A port can be reused only if it has been closed completelySHUT_RD or0stop all read operations on this socket, but continue writing SHUT_WR or1stop all write operations on this socket, but keep receiving data SHUT_RDWR or2same as close Multiple Sockets
Suppose we have a process which has to handle multiple sockets. We cannot simply read from one of them if a request comes, because that will block while waiting on the request on that particular socket. In the meantime a request may come on any other socket. To handle this input/output multiplexing we could use different techniques : - Busy waiting: In this methodology we make all the operations
on sockets non-blocking and handle them simultaneously by doing polling.
For example, we could use the read() system call this way and read from
all the sockets together. The disadvantage in this is that we waste a
lot of CPU cycles. To make the system calls non-blocking we use:
fcntl (s, f_setfl, fndelay);
- Asynchronous I/O: Here we ask the Operating System
to tell us whenever we are waiting for I/O on some sockets. The
Operating System sends a signal whenever there is some I/O. When we
receive a signal, we will have to check all sockets and then wait till
the next signal comes. But there are two problems - first, the signals
are expensive to catch and second, we would not be able to know if an
input comes on a socket when we are doing I/O on another one. For
Asynchronous I/O, we have a different set of commands (here we give the
ones for UNIX with a VHD variant):
signal(sigio, io_handler);
fcntl(s, f_setown, getpid());
fcntl(s, f_setfl, fasync);
- Separate process for each I/O: We could as well fork out 10 different child processes for 10 different sockets. These child processes are very light weight and have some communication between them. Now these processes waiting on each socket can have blocking system calls. This wastes a lot of memory, data structures and other resources.
- Select() system call: We can use the select system call
to instruct the Operating System to wait for any one of multiple events
to occur and to wake up the process only if one of these events occur.
This way we would know that the I/O request has come from which socket.
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *errorfds, struct timeval *timeout);
void FD_CLR(int fd, fd_set *fdset);
int FD_ISSET(int fd, fd_set *fdset);
void FD_SET(int fd, fd_set *fdset);
void FD_ZERO(fd_set *fdset);
The select() function indicates which of the specified file descriptors is ready for reading, ready for writing, or has an error condition pending. If the specified condition is false for all of the specified file descriptors, select() blocks up to the specified timeout interval, until the specified condition is true for at least one of the specified file descriptors. The nfds argument specifies the range of file descriptors to be tested. The select() function tests file descriptors in the range of 0 to nfds-1. readfds, writefds and errorfds arguments point to an object of type fd_set. readfds specifies the file descriptors to be checked for being ready to read. writefds specifies the file descriptors to be checked for being ready to write, errorfds specifies the file descriptors to be checked for error conditions pending.
On successful completion, the objects pointed to by the readfds, writefds, and errorfds arguments are modified to indicate which file descriptors are ready for reading, ready for writing, or have an error condition pending, respectively. For each file descriptor less than nfds, the corresponding bit will be set on successful completion if it was set on input and the associated condition is true for that file descriptor. The timeout is an upper bound on the amount of time elapsed before select returns. It may be zero, causing select to return immediately. If the timeout is a null pointer, select() blocks until an event causes one of the masks to be returned with a valid (non-zero) value. If the time limit expires before any event occurs that would cause one of the masks to be set to a non-zero value, select() completes successfully and returns 0.
Reserved Ports
Port numbers from 1-1023 are reserved for the superuser and the rest of the ports starting from 1024 are for other users. But we have a finer division also which is as follows :- 1 to 511 - these are assigned to the processes run by the superuser
- 512 to 1023 - they are used when we want to assign ports to some important user or process but want to show that this is a reserved superuser port
- 1024 to 5000 - they are system assigned random ports
- 5000 to FFFF - they are used to assign a port to user processes or sockets used by users
Some Topics in TCP
Acknowledgement Ambiguity Problem
There can be an ambiguous situation during the Retransmission time-out for a packet . Such a case is described below:The events are :
1. A packet named 'X' is sent at time 't1' for the first time .
2. Timeout occours for 'X' and acknowledgement is not recieved .
3. So 'X' will be retransmitted at time 't2' .
4. The acknowledgment arrives at 't' .
In this case , we cannot be sure wether the acknowledgement recieved at 't' is for the packet 'X' sent at the time 't1' or 't2'. What should be our RTT sample value?
If we take ('t'-'t1' ) as the RTT sample :
t2-t1 (timeout period) is typically much greater than the average RTT . This implies that if we take t-t1 , then it will tend to increase the average RTT . If this happens for a large number of packets then the RTT will increase significantly. Now as the RTT increases , the timeout value increases and the damage caused by the above sequence of events increases . So this may cause the timeout to become very large unnecessarily .
If we take 't'-'t2' as the RTT sample :
Consider the case in which the acknowledgement for a packet takes a lot more time to arrive as compared to the timeout value . That is , the acknowledgement that arrives is for the packet which had been sent at the time 't1'.
That implies t-t2 is likely to be smaller and hence will tend to decrease the value of the RTT when included as a sample . A string of such events would cause the timeout to decrease . As the timeout decreases , the above sequence of events becomes more probable leading to even a further decrease in timeout . So if we consider t-t2, the timeout may become very small .
Since both the cases may lead to some problems , one possible solution is to discard the sample for which timeout occours . But this can't be done!!If the packet gets lost , the network is most probaaly congested The previous estimate of RTT is now meaningless as it was for an uncongested network and the characteristics of the network have changed Also new samples cant be found due to the above ambiguity .
So we simply adopt the policy of doubling the value of RTO on packet loss . When the congestion in the network subisdes , then we can start sampling afresh or we can go back to the state before the congestion occurred .
Note that this is a temporary increase in the value of RTO, as we have not increased the value of RTT. So, the present RTT value will help us to go back to the previous situation when it becomes normal.
This is called the Acknowledgment Ambiguity Problem.
Fast Restransmit
TCP may generate an immediate acknowledgment (a duplicate ACK) when an out- of-order segment is received. This duplicate ACK should not be delayed. The purpose of this duplicate ACK is to let the other end know that a segment was received out of order, and to tell it what sequence number is expected. Since TCP does not know whether a duplicate ACK is caused by a lost segment or just a reordering of segments, it waits for a small number of duplicate ACKs to be received. It is assumed that if there is just a reordering of the segments, there will be only one or two duplicate ACKs before the reordered segment is processed, which will then generate a new ACK. If three or more duplicate ACKs are received in a row, it is a strong indication that a segment has been lost. TCP then performs a retransmission of what appears to be the missing segment, without waiting for a retransmission timer to expire. This algorithm is one of the algorithms used by the TCP for the purpose of Congestion/Flow Control. Let us consider ,a sender has to send packets with sequence numbers from 1 to 10 (Please note ,in TCP the bytes are given sequence numbers, but for the sake of explanation the example is given). Suppose packet 4 got lost.How will the sender know that it is lost ?
The sender must have received the cumulative acknowledgment for packet 3. Now, time-out for packet 4 occurs. On the receiver side, the packet 5 is received. As it is an out of sequence packet, the duplicate acknowledgment (thanks to it's cumulative nature) is not delayed and sent immediately. The purpose of this duplicate ACK is to let the other end know that a segment was received out of order, and to tell it what sequence number is expected. So, now the sender sees a duplicate ACK. But can it be sure that the packet 4 was lost ?
Well, no as of now. Various situations like duplication of packet 3 or ACK itself, delay of packet 4 or receipt of an out of sequence packet etc. might have resulted in a duplicate ACK.
So, what does it do? Wait for more!!! Yeah, it waits for more duplicate packets. It is assumed that if there is just a reordering of the segments, there will be only one or two duplicate ACKs before the reordered segment is processed, which will then generate a new ACK. If three or more duplicate ACKs are received in a row, it is a strong indication that a segment has been lost. TCP then performs a retransmission of what appears to be the missing segment, without waiting for a retransmission timer to expire. This is called Fast Retransmit.
Flow Control
Both the sender and the receiver can specify the number of packets they are ready to send/receive. To implement this, the receiver advertises a Receive Window Size. Thus with every acknowledgment, the receiver sends the number of packets that it is willing to accept. Note that the size of the window depends on the available space in the buffer on the receiver side. Thus, as the application keeps consuming the data, window size is incremented.On the sender size, it can use the acknowledgment and the receiver's window size to calculate the sequence number up to which it is allowed to transmit. For ex. If the acknowledgment is for packet 3 and the window size is 7, the sender knows that the recipient has received data up to packet 3 and it can send packets of sequence number up to (7+3=10).
The problem with the above scheme is that it is too fast. Suppose, in the above example, the sender sends 7 packets together and the network is congested. So, some packets may be lost. The timer on the sender side goes off and now it again sends 7 packets together, thus increasing the congestion further more. It only escalates the magnitude of the problem.
Image References
- http://publib.boulder.ibm.com/iseries/v5r1/ic2924/info/rzab6/rxab6502.gif
if u like the post just say thank u in comment box.
No comments:
Post a Comment
its cool