click here complete Lecture Notes: Computer Networks
Network Layer
What is Network Layer?
The network layer is concerned with getting packets from the source all the way to the destination. The packets may require to make many hops at the intermediate routers while reaching the destination. This is the lowest layer that deals with end to end transmission. In order to achieve its goals, the network layer must know about the topology of the communication network. It must also take care to choose routes to avoid overloading of some of the communication lines while leaving others idle. The network layer-transport layer interface frequently is the interface between the carrier and the customer, that is the boundary of the subnet. The functions of this layer include :- Routing - The process of transferring packets received from the Data Link Layer of the source network to the Data Link Layer of the correct destination network is called routing. Involves decision making at each intermediate node on where to send the packet next so that it eventually reaches its destination. The node which makes this choice is called a router. For routing we require some mode of addressing which is recognized by the Network Layer. This addressing is different from the MAC layer addressing.
- Inter-networking - The network layer is the same across all physical networks (such as Token-Ring and Ethernet). Thus, if two physically different networks have to communicate, the packets that arrive at the Data Link Layer of the node which connects these two physically different networks, would be stripped of their headers and passed to the Network Layer. The network layer would then pass this data to the Data Link Layer of the other physical network..
- Congestion Control - If the incoming rate of the packets arriving at any router is more than the outgoing rate, then congestion is said to occur. Congestion may be caused by many factors. If suddenly, packets begin arriving on many input lines and all need the same output line, then a queue will build up. If there is insufficient memory to hold all of them, packets will be lost. But even if routers have an infinite amount of memory, congestion gets worse, because by the time packets reach to the front of the queue, they have already timed out (repeatedly), and duplicates have been sent. All these packets are dutifully forwarded to the next router, increasing the load all the way to the destination. Another reason for congestion are slow processors. If the router's CPUs are slow at performing the bookkeeping tasks required of them, queues can build up, even though there is excess line capacity. Similarly, low-bandwidth lines can also cause congestion.
Addressing Scheme
IP addresses are of 4 bytes and consist of :
i) The network address, followed by
ii) The host address
The first part identifies a network on which the host resides and the second part identifies the particular host on the given network. Some nodes which have more than one interface to a network must be assigned separate internet addresses for each interface. This multi-layer addressing makes it easier to find and deliver data to the destination. A fixed size for each of these would lead to wastage or under-usage that is either there will be too many network addresses and few hosts in each (which causes problems for routers who route based on the network address) or there will be very few network addresses and lots of hosts (which will be a waste for small network requirements). Thus, we do away with any notion of fixed sizes for the network and host addresses.
We classify networks as follows:
- Large Networks : 8-bit network address and 24-bit host address. There are approximately 16 million hosts per network and a maximum of 126 ( 2^7 - 2 ) Class A networks can be defined. The calculation requires that 2 be subtracted because 0.0.0.0 is reserved for use as the default route and 127.0.0.0 be reserved for the loop back function. Moreover each Class A network can support a maximum of 16,777,214 (2^24 - 2) hosts per network. The host calculation requires that 2 be subtracted because all 0's are reserved to identify the network itself and all 1s are reserved for broadcast addresses. The reserved numbers may not be assigned to individual hosts.
- Medium Networks : 16-bit network address and 16-bit host address. There are approximately 65000 hosts per network and a maximum of 16,384 (2^14) Class B networks can be defined with up to (2^16-2) hosts per network.
- Small networks : 24-bit network address and 8-bit host address. There are approximately 250 hosts per network.
Address Classes
- The IP specifications divide addresses into the following classes :
-
Class A - For large networks
0 7 bits of the network address 24 bits of host address
-
Class B - For medium networks
1 0 14 bits of the network address 16 bits of host address
-
Class C - For small networks
1 1 0 21 bits of the network address 8 bits of host address
-
Class D - For multi-cast messages ( multi-cast to a "group" of networks )
1 1 1 0 28 bits for some sort of group address
-
Class E - Currently unused, reserved for potential uses in the future
1 1 1 1 28 bits
Internet Protocol
Special Addresses : There are some special IP addresses :- Broadcast Addresses
They are of two types :
(i) Limited Broadcast : It consists of all 1's, i.e., the address is 255.255.255.255 . It is used only on the LAN, and not for any external network.
(ii) Directed Broadcast : It consists of the network number + all other bits as1's. It reaches the router corresponding to the network number, and from there it broadcasts to all the nodes in the network. This method is a major security problem, and is not used anymore. So now if we find that all the bits are 1 in the host no. field, then the packet is simply dropped. Therefore, now we can only do broadcast in our own network using Limited Broadcast. - Network ID = 0
It means we are referring to this network and for local broadcast we make the host ID zero. - Host ID = 0
This is used to refer to the entire network in the routing table. - Loop-back Address
Here we have addresses of the type 127.x.y.z It goes down way upto the IP layer and comes back to the application layer on the same host. This is used to test network applications before they are used commercially.
Sub netting means organizing hierarchies within the network by dividing the host ID as per our network. For example consider the network ID : 150.29.x.y
We could organize the remaining 16 bits in any way, like :
4 bits - department
4 bits - LAN
8 bits - host
This gives some structure to the host IDs. This division is not visible to the outside world. They still see just the network number, and host number (as a whole). The network will have an internal routing table which stores information about which router to send an address to. Now consider the case where we have : 8 bits - subnet number, and 8 bits - host number. Each router on the network must know about all subnet numbers. This is called the subnet mask. We put the network number and subnet number bits as 1 and the host bits as 0. Therefore, in this example the subnet mask becomes : 255.255.255.0 . The hosts also need to know the subnet mask when they send a packet. To find if two addresses are on the same subnet, we can AND source address with subnet mask, and destination address with with subnet mask, and see if the two results are the same. The basic reason for sub netting was avoiding broadcast. But if at the lower level, our switches are smart enough to send directed messages, then we do not need sub netting. However, sub netting has some security related advantages.
Supernetting
This is moving towards class-less addressing. We could say that the network number is 21 bits ( for 8 class C networks ) or say that it is 24 bits and 7 numbers following that. For example : a.b.c.d / 21 This means only look at the first 21 bits as the network address.
Addressing on IITK Network
If we do not have connection with the outside world directly then we could have Private IP addresses ( 172.31 ) which are not to be publicised and routed to the outside world. Switches will make sure that they do not broadcast packets with such addressed to the outside world. The basic reason for implementing subnetting was to avoid broadcast. So in our case we can have some subnets for security and other reasons although if the switches could do the routing properly, then we do not need subnets. In the IITK network we have three subnets -CC, CSE building are two subnets and the rest of the campus is one subset Packet Structure
Version Number (4 bits)
|
Header Length (4 bits)
|
Type of Service (8 bits)
|
Total Length (16 bits)
|
|
ID (16 bits)
|
Flags (3bits)
|
Flag Offset (13 bits)
|
||
Time To Live (8 bits)
|
Protocol (8 bits)
|
Header Checksum (16 bits)
|
||
Source (32 bits)
|
||||
Destination (32 bits)
|
||||
|
||||
- Version Number : The current version is Version 4 (0100).
- Header Length : We could have multiple sized headers so we need this field. Header will always be a multiple of 4bytes and so we can have a maximum length of the field as 15, so the maximum size of the header is 60 bytes ( 20 bytes are mandatory ).
-
Type Of Service (ToS) : This helps the router in taking the right routing decisions. The structure is :
First three bits : They specify the precedences i.e. the priority of the packets.
Next three bits :- D bit - D stands for delay. If the D bit is set to 1, then
this means that the application is delay sensitive, so we should try to
route the packet with minimum delay.
- T bit - T stands for throughput. This tells us that this particular operation is throughput sensitive.
- R bit - R stands for reliability. This tells us that we should route this packet through a more reliable network.
- ID Field : The source and ID field together will represent the fragments of a unique packet. So each fragment will have a different ID.
- Offset : It is a 13 bit field that represents where in the packet, the current fragment starts. Each bit represents 8 bytes of the packet. So the packet size can be at most 64 kB. Every fragment except the last one must have its size in bytes as a multiple of 8 in order to ensure compliance with this structure. The reason why the position of a fragment is given as an offset value instead of simply numbering each packet is because refragmentation may occur somewhere on the path to the other node. Fragmentation, though supported by IPv4 is not encouraged. This is because if even one fragment is lost the entire packet needs to be discarded. A quantity M.T.U (Maximum Transmission Unit) is defined for each link in the route. It is the size of the largest packet that can be handled by the link. The Path-M.T.U is then defined as the size of the largest packet that can be handled by the path. It is the smallest of all the MTUs along the path. Given information about the path MTU we can send packets with sizes smaller than the path MTU and thus prevent fragmentation. This will not completely prevent it because routing tables may change leading to a change in the path.
- Flags :It has three bits -
- M bit : If M is one, then there are more fragments on the way and if M is 0, then it is the last fragment
- DF bit : If this bit is sent to 1, then we should not fragment such a packet.
- Reserved bit : This bit is not used.
- Total Length : It includes the IP header and everything that comes after it.
- Time To Live (TTL) : Using this field, we can set the time within which the packet should be delivered or else destroyed. It is strictly treated as the number of hops. The packet should reach the destination in this number of hops. Every router decreases the value as the packet goes through it and if this value becomes zero at a particular router, it can be destroyed.
- Protocol : This specifies the module to which we should hand over the packet ( UDP or TCP ). It is the next encapsulated protocol.
Value Protocol
0 Pv6 Hop-by-Hop Option.
1 ICMP, Internet Control Message Protocol.
2 IGMP, Internet Group Management Protocol. RGMP, Router-port Group Management Protocol.
3 GGP, Gateway to Gateway Protocol.
4 IP in IP encapsulation.
5 ST, Internet Stream Protocol.
6 TCP, Transmission Control Protocol.
7 UCL, CBT.
8 EGP, Exterior Gateway Protocol.
9 IGRP.
10 BBN RCC Monitoring.
11 NVP, Network Voice Protocol.
12 PUP.
13 ARGUS.
14 EMCON, Emission Control Protocol.
15 XNET, Cross Net Debugger.
16 Chaos.
17 UDP, User Datagram Protocol.
18 TMux, Transport Multiplexing Protocol.
19 DCN Measurement Subsystems.
-
-
255
- Header Checksum : This is the usual checksum field used to detect errors. Since the TTL field is changing at every router so the header checksum ( upto the options field ) is checked and recalculated at every router.
- Source : It is the IP address of the source node
- Destination : It is the IP address of the destination node.
- IP Options :
The options field was created in order to allow features to be added into IP as time passes and requirements change.
Currently 5 options are specified although not all routers support them. They are:
- Securtiy: It tells us how secret the information is. In theory a military router might use this field to specify not to route through certain routers. In practice no routers support this field.
- Source Routing: It is used when we want the source to dictate how the packet traverses the network. It
is of 2 types
-> Loose Source Record Routing (LSRR): It requires that the packet traverse a list of specified routers, in the order specified but the packet may pass though some other routers as well.
-> Strict Source Record Routing (SSRR): It requires that the packet traverse only the set of specified routers and nothing else. If it is not possible, the packet is dropped with an error message sent to the host.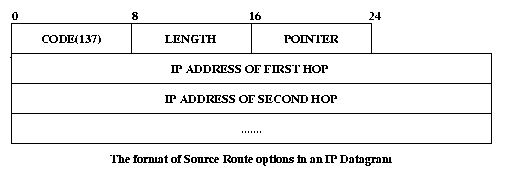
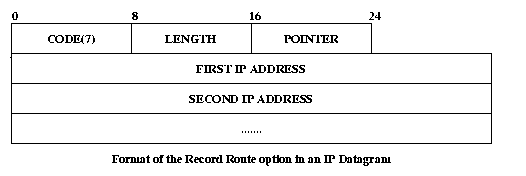
The above is the format for SSRR. For LSRR the code is 131. - Record Routing :
- Time Stamp Routing :
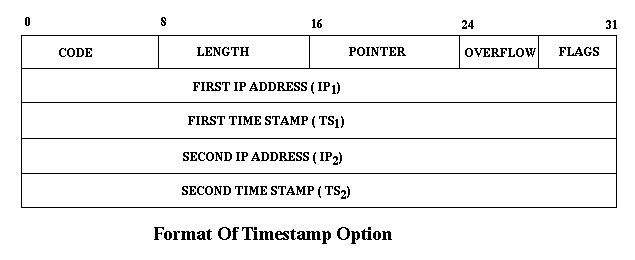
-> Flags: It can have the following values- 0- Enter only timestamp.
- 1- The nodes should enter Timestamp as well as their IP.
- 3 - The source specifies the IPs that should enter their timestamp. A special point of interest is that only if the IP is the same as that at the pointer then the time is entered. Thus if the source specifies IP1 and IP2 but IP2 is first in the path then the field IP2 is left empty, even after having reached IP2 but before reaching IP1.
- Format of the type/code field
Copy Bit Type of option Option Number. - Copy bit: It says whether the option is to be copied to every fragment or not. a value of 1 stands for copying and 0 stands for not copying.
- Type: It is a 2 bit field. Currently specified values are 0 and 2. 0 means the option is a control option while 2 means the option is for measurement
- Option Number: It is a 5 bit field which specifies the option number.
- TLV: Type/Length/Value. This format is followed in not only in IP but in nearly all major protocols.
- Routing
- Congestion Control
- Internetwokring
Routing
Routing is the process of forwarding of a packet in a network so that it reaches its intended destination. The main goals of routing are:- Correctness: The routing should be done properly and correctly so that the packets may reach their proper destination.
- Simplicity: The routing should be done in a simple manner so that the overhead is as low as possible. With increasing complexity of the routing algorithms the overhead also increases.
- Robustness: Once a major network becomes operative, it may be expected to run continuously for years without any failures. The algorithms designed for routing should be robust enough to handle hardware and software failures and should be able to cope with changes in the topology and traffic without requiring all jobs in all hosts to be aborted and the network rebooted every time some router goes down.
- Stability: The routing algorithms should be stable under all possible circumstances.
- Fairness: Every node connected to the network should get a fair chance of transmitting their packets. This is generally done on a first come first serve basis.
- Optimality: The routing algorithms should be optimal in terms of throughput and minimizing mean packet delays. Here there is a trade-off and one has to choose depending on his suitability.
Classification of Routing Algorithms
The routing algorithms may be classified as follows:- Adaptive Routing Algorithm: These algorithms change their
routing decisions to reflect changes in the topology and in traffic as
well. These get their routing information from adjacent routers or from
all routers. The optimization parameters are the distance, number of
hops and estimated transit time. This can be further classified as
follows:
- Centralized: In this type some central node in the network gets entire information about the network topology, about the traffic and about other nodes. This then transmits this information to the respective routers. The advantage of this is that only one node is required to keep the information. The disadvantage is that if the central node goes down the entire network is down, i.e. single point of failure.
- Isolated: In this method the node decides the routing
without seeking information from other nodes. The sending node does not
know about the status of a particular link. The disadvantage is that
the packet may be send through a congested route resulting in a delay.
Some examples of this type of algorithm for routing are:
- Hot Potato: When a packet comes to a node, it tries to get rid of it as fast as it can, by putting it on the shortest output queue without regard to where that link leads. A variation of this algorithm is to combine static routing with the hot potato algorithm. When a packet arrives, the routing algorithm takes into account both the static weights of the links and the queue lengths.
- Backward Learning: In this method the routing tables at each node gets modified by information from the incoming packets. One way to implement backward learning is to include the identity of the source node in each packet, together with a hop counter that is incremented on each hop. When a node receives a packet in a particular line, it notes down the number of hops it has taken to reach it from the source node. If the previous value of hop count stored in the node is better than the current one then nothing is done but if the current value is better then the value is updated for future use. The problem with this is that when the best route goes down then it cannot recall the second best route to a particular node. Hence all the nodes have to forget the stored informations periodically and start all over again.
- Distributed: In this the node receives information from its neighbouring nodes and then takes the decision about which way to send the packet. The disadvantage is that if in between the the interval it receives information and sends the paket something changes then the packet may be delayed.
- Non-Adaptive Routing Algorithm: These algorithms do
not base their routing decisions on measurements and estimates of the
current traffic and topology. Instead the route to be taken in going
from one node to the other is computed in advance, off-line, and
downloaded to the routers when the network is booted. This is also known
as static routing. This can be further classified as:
- Flooding: Flooding adapts the technique in which every
incoming packet is sent on every outgoing line except the one on which
it arrived. One problem with this method is that packets may go in a
loop. As a result of this a node may receive several copies of a
particular packet which is undesirable. Some techniques adapted to
overcome these problems are as follows:
- Sequence Numbers: Every packet is given a sequence number. When a node receives the packet it sees its source address and sequence number. If the node finds that it has sent the same packet earlier then it will not transmit the packet and will just discard it.
- Hop Count: Every packet has a hop count associated with it. This is decremented(or incremented) by one by each node which sees it. When the hop count becomes zero(or a maximum possible value) the packet is dropped.
- Spanning Tree: The packet is sent only on those links that lead to the destination by constructing a spanning tree routed at the source. This avoids loops in transmission but is possible only when all the intermediate nodes have knowledge of the network topology.
- Random Walk: In this method a packet is sent by the node to one of its neighbours randomly. This algorithm is highly robust. When the network is highly interconnected, this algorithm has the property of making excellent use of alternative routes. It is usually implemented by sending the packet onto the least queued link.
click here complete Lecture Notes: Computer Networks
- Flooding: Flooding adapts the technique in which every
incoming packet is sent on every outgoing line except the one on which
it arrived. One problem with this method is that packets may go in a
loop. As a result of this a node may receive several copies of a
particular packet which is undesirable. Some techniques adapted to
overcome these problems are as follows:
Delta Routing
Delta routing is a hybrid of the centralized and isolated routing algorithms. Here each node computes the cost of each line (i.e some functions of the delay, queue length, utilization, bandwidth etc) and periodically sends a packet to the central node giving it these values which then computes the k best paths from node i to node j. Let Cij1 be the cost of the best i-j path, Cij2 the cost of the next best path and so on.If Cijn - Cij1 < delta, (Cijn - cost of n'th best i-j path, delta is some constant) then path n is regarded equivalent to the best i-j path since their cost differ by so little. When delta -> 0 this algorithm becomes centralized routing and when delta -> infinity all the paths become equivalent.Multipath Routing
In the above algorithms it has been assumed that there is a single best path between any pair of nodes and that all traffic between them should use it. In many networks however there are several paths between pairs of nodes that are almost equally good. Sometimes in order to improve the performance multiple paths between single pair of nodes are used. This technique is called multipath routing or bifurcated routing. In this each node maintains a table with one row for each possible destination node. A row gives the best, second best, third best, etc outgoing line for that destination, together with a relative weight. Before forwarding a packet, the node generates a random number and then chooses among the alternatives, using the weights as probabilities. The tables are worked out manually and loaded into the nodes before the network is brought up and not changed thereafter.Hierarchical Routing
In this method of routing the nodes are divided into regions based on hierarchy. A particular node can communicate with nodes at the same hierarchial level or the nodes at a lower level and directly under it. Here, the path from any source to a destination is fixed and is exactly one if the heirarchy is a tree.click here complete Lecture Notes: Computer Networks
if u like the post just say thank u in comment box.
No comments:
Post a Comment
its cool